

Reading and understanding database execution plans
Following a Plan
The execution plan (often called the query execution plan or the explain plan) contains the individual steps a database goes through to execute a SQL statement. For example, execution plans provide information on which indexes are used, in which order access to the various tables occurs, and what algorithms are used for joins, sorting, and grouping operations.
The execution plan roughly corresponds to bytecode in scripting languages like Perl or Python – it is used internally to execute SQL statements. Creating an execution plan is sometimes also known as a compiling. However, this is more commonly referred to as the prepare phase (Figure 1). Because the corresponding database component is known as the optimizer or query planner, the terms optimize and plan are also commonly used.

Execution plans are, first and foremost, an internal means to an end, but admins can still view them. Because the execution plan represents processes on a similar level of abstraction as SQL, you can read an execution plan very quickly and – because it's consistently formatted by the database – often even faster than the original SQL statement.
However, execution plan formatting is only uniform for a single database. There is no such thing as a vendor-independent standard. In fact, the execution plans of a MySQL database look completely different from a plan for Microsoft's SQL Server. Just as different are the methods for displaying execution plans. Although it is sufficient in PostgreSQL and MySQL to precede the SQL statement with the explain keyword, Oracle uses the explain plan for command in combination with the DBMS_XPLAN.DISPLAY function call (see Example 1).
Graphical user interfaces provide appropriate buttons or menu items for this. This article focuses on MySQL (although references for other products can be found on the Internet [1]). I'll show you how the admin can retrieve the most important facts from an execution plan and how to avoid typical misinterpretations.
Cost Value
The cost value is a benchmark used by the optimizer to identify the best execution plan for a SQL statement. You could say that the cost value is a scale for the execution speed. The cost value only applies to one SQL statement under certain conditions, one of them being the table size. This means that the cost value basically is not suitable for comparing the performance of different SQL instructions.
Nevertheless, the cost value can still give you a rough idea of the execution speed. A value in the billions can thus allow you to infer that execution will take forever. The cost value is only the indicator, not the cause, because it does not affect the execute phase.
Something similar applies for the purpose of optimizing statistics. Because these statistics are the basis for computing the cost value, updating them will also change the cost value. In spite of this, the speed of the SQL query will not change if the execution plan remains otherwise unchanged – that is, if the same operations are still processed in the same order.
Using Indexes
Another misinterpretation of execution plans has something to do with the use of indexes. People often have the idea that an index will accelerate execution as a matter of principle. But this is only half the truth.
In some cases, an index can actually slow down execution – mainly in queries that read a relatively large part of a table. Using an index would cause many reads against small data blocks. If the database fully reads the table instead, it can request larger blocks of data at once and thus reduce the number of read operations, which can translate to better performance because both the throughput and the IOPS (Input/Output operations per second) are limited on storage systems. Incidentally, the cost value is used to decide whether an index is useful or harmful: The database uses it to evaluate both execution plan variants and selects the one with the better cost value.
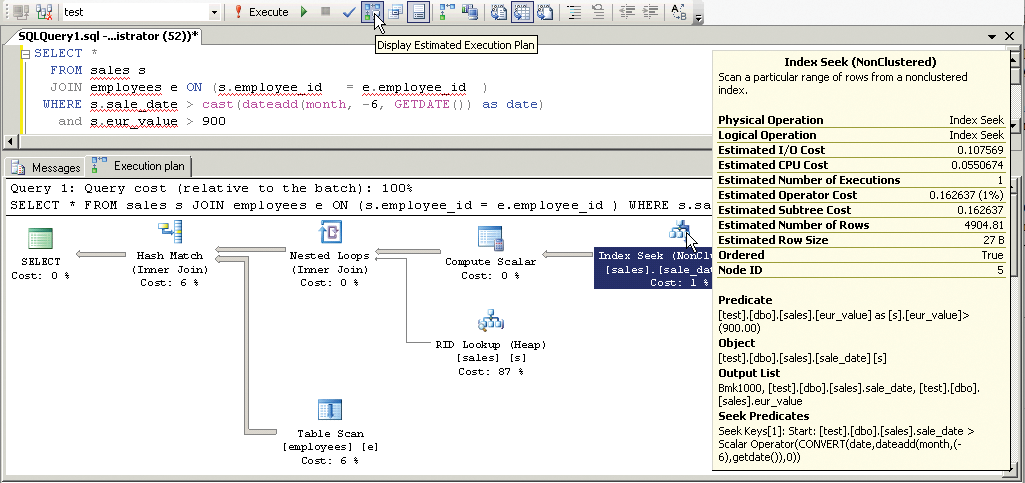
The execution plan doesn't just tell you which index is used. Execution plans also tell you something about the effectiveness of accessing the index, which largely depends on which parts of the WHERE clause are covered by the index. With some databases, you can discover this information directly from the execution plan by looking at the filter predicates. If a filter predicate occurs in table access, it can indicate that the column in question is missing from the index (Examples 1 and 3).
Filter predicates for an index access can also be a sign of wrong column order (as shown in Example 2). The query only uses the index optimally if the access predicate or seek predicate is displayed.
Something similar to filter and access predicates occurs when searching in a printed phone book if you only know the last name and the address of the person you are seeking. The first step (e.g., finding all of the entries for "Smith") is completed very quickly. Because of the way the phone book is sorted, you can quickly browse forward and backward until you find the Smith section. If you look at this more closely, you are performing a binary search, for which overhead only grows logarithmically with the size of the phone book. In other words, if the phone book were 10 times as big, the search would not take 10 times as long.
In a database, the condition Last Name= 'Smith' would therefore be an access predicate. After finding the Smiths, you still need to find a particular Smith using the known address; however, without a first name, you cannot continue to use the phone book's sorted listing. The only option is to go through all the Smiths. In a database, the condition would thus be a filter predicate. The search time increases linearly with the number of Smiths.
The difference between access and filter predicates is often underestimated, but it could well be considerable. Figure 2 shows the performance difference. In an ideal case – for example, if access predicates can be used throughout – the speed can still remain almost constant (shown in green) despite a rapidly growing table. The more filter predicates are used, the greater influence the table size has on the speed (shown in red). That is, filter and access predicates let you forecast the speed for a growing data volume and thus identify problems before they happen. The cause of the massive performance difference in the figure, by the way, is the result of swapping the second and third columns in the index.

A holistic approach is essential in database indexing. In particular, changing the column order is dangerous because it can make the index unusable for other queries. Index changes must therefore be tested extensively, planned carefully, and of course, clarified with the application vendor.
Memory Requirements
A less known, but not less useful, fact is that execution plans can also tell you something about the memory footprint of an SQL query – that is, about how much RAM is required for execution. To do so, you break down the operations displayed in the execution plan into two categories:
- those that generally only have a small memory footprint and
- those that cache intermediate results in memory and thus have a potentially large memory footprint.
In resource planning, you obviously only need to worry about the second category, which mainly means sorting and grouping operations, but also any operations that use a hash algorithm – such as hash join. Although the names of these operations differ in the various database products (see Example 4), the most memory-intensive operations are usually betrayed by the sort, group, or hash component in their names. However, there are also special cases such as the SORT GROUP BY NOSORT operation in the Oracle database, which does not perform a sort but a group by on pre-sorted data.
The good thing about execution plans is that they explicitly show implicit sorts. For example, if you accidentally combine two tables using UNION, the execution plan also shows the operation for deduplicating the results (exception: MySQL). However, if by the nature of the data no duplicates can occur – and thus a UNION ALL is sufficient – this operation and its related memory footprint will disappear.
Likewise, a corresponding group or hash operation is displayed for a DISTINCT, and again this behavior is associated with a certain memory footprint.
Conversely, there are also cases in which databases do not perform a seemingly necessary sort operation. It can happen that, despite an order by clause in the SQL query, no sort operation occurs in the execution plan. This outcome is usually because of clever indexing that ensures the index provides the data in the desired order. This technique is often combined with limit or top clauses and ideally almost completely decouples the resource requirements from the table size. Thus, the speed of a query without a where clause can actually be independent of the table size if the order by and limit/top clauses are combined with a matching index. Obviously, you can't see this optimization by looking at the SQL query itself, but in the execution plan, you will identify this technique by the missing sort operation.
Conclusions
Administrators and SQL developers need to master execution plans, purely because of what an execution plan can reveal about a database. The execution plan is an important tool that can help you identify and promptly fix the causes of database performance issues.